On April 3, 2026, Andrej Karpathy — former head of AI at Tesla and one of the founding members of OpenAI — shared an architecture proposal that cuts against the grain of how most companies deploy AI systems today. He calls it the LLM Knowledge Base, and it replaces the now-ubiquitous Retrieval-Augmented Generation (RAG) pipeline with something radically simpler: a curated, evolving library of markdown documents maintained by AI agents and loaded directly into the LLM's context window.
No vector database. No embedding pipeline. No retrieval step.
If you've spent any time building or maintaining a RAG system — and at Cloud Radix, we've built more than a few — you know the pain points. Chunking strategies that fragment meaning. Embedding models that silently drift. Retrieval failures that produce confident-sounding hallucinations. A RAG pipeline is powerful, but it's also fragile and opaque in ways that make business stakeholders uncomfortable.
Karpathy's proposal asks a deceptively simple question: what if the knowledge base itself were the interface? What if, instead of building an elaborate search-and-retrieve system, you had AI agents continuously maintain structured, human-readable documents — and then just handed those documents to the model?
This isn't a theoretical exercise. With modern LLMs supporting context windows of 100K to over 1 million tokens, loading a substantial organizational knowledge base directly into context is now technically feasible. And the implications for how businesses deploy AI employees are significant.
Key Takeaways
- Karpathy's LLM Knowledge Base architecture replaces traditional RAG pipelines with curated markdown documents loaded directly into LLM context windows.
- AI agents continuously maintain and update structured knowledge documents, creating "pre-digested" information the model can use without retrieval.
- The approach is simpler to build, easier to audit, and more accessible to non-technical teams than conventional RAG systems.
- Growing context windows (100K–1M+ tokens) make this architecture practical for real business use cases.
- This doesn't eliminate RAG entirely — but it reshapes when and why you'd use it.

What Is the LLM Knowledge Base Architecture, and How Does It Work?
To understand what Karpathy is proposing, it helps to first lay out what it replaces.
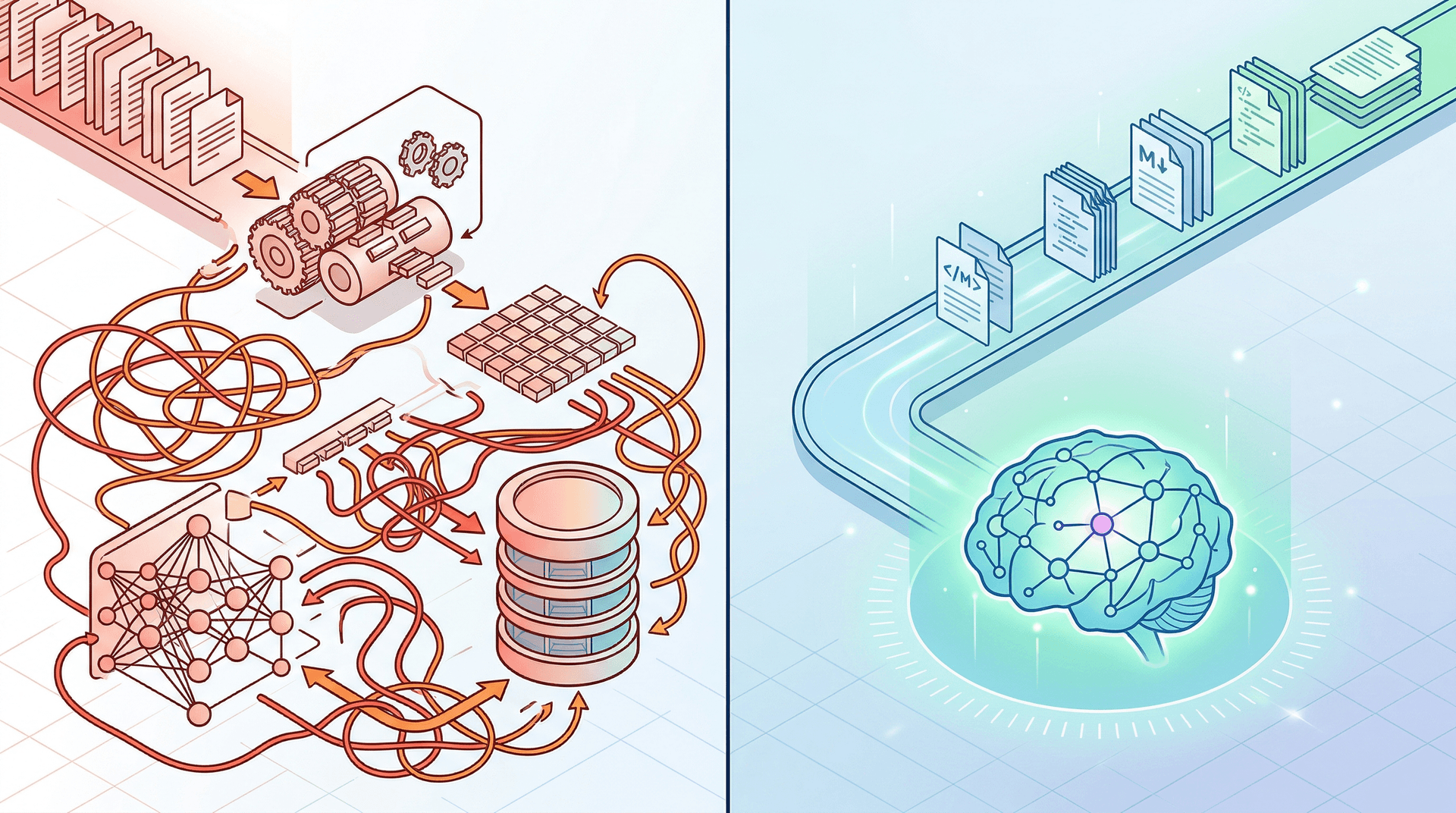
The traditional RAG pipeline follows a well-established pattern. You take your organizational documents — policies, product manuals, customer records, knowledge articles — and run them through a series of steps:
- Document ingestion — collecting and standardizing raw documents.
- Chunking — splitting documents into smaller segments, typically 256–1024 tokens each.
- Embedding — converting those chunks into numerical vector representations using an embedding model.
- Vector storage — indexing those embeddings in a vector database like Pinecone, Weaviate, or Chroma.
- Retrieval — at query time, embedding the user's question and finding the most semantically similar chunks.
- Context injection — passing those retrieved chunks to the LLM alongside the question.
- Generation — the LLM produces an answer based on the retrieved context.
Each of these steps introduces potential failure modes. Chunking can split a critical paragraph in half. Embedding models can represent two very different concepts as similar. Retrieval can return the second-best match instead of the best one. And the user never sees any of it happening.
The LLM Knowledge Base architecture collapses this entire pipeline into something far more direct:
- AI agents continuously read, summarize, and organize raw organizational documents into structured markdown files.
- These markdown files form a curated knowledge library — organized by topic, kept current, written in clear language.
- At query time, the relevant markdown documents are loaded directly into the LLM's context window.
- The LLM generates its response with full, explicit context — no retrieval step, no vector math, no embedding.
The key insight is that the AI agents do the hard work upfront. They "pre-digest" raw information into structured, coherent documents that the model can reason over directly. The knowledge base isn't a database — it's a library that both humans and machines can read.
As VentureBeat reported on April 3, this approach leverages the fact that modern context windows are now large enough to hold meaningful amounts of organizational knowledge without any retrieval mechanism at all.
Why Does RAG Keep Failing in Production, and What Does This Architecture Fix?
RAG isn't bad. It's been the go-to architecture for grounding LLMs in organizational data for good reason — it works, especially when your document corpus is too large to fit in any context window. But production RAG systems have persistent failure modes that most teams encounter sooner or later.
Chunking artifacts. When you split a document into fixed-size chunks, you inevitably break some ideas in half. A policy that says "Employees may work remotely, except during the first 90 days of employment" might get split so that only "Employees may work remotely" makes it into the retrieved chunk. The LLM then confidently gives wrong information, and nobody in the pipeline catches it because the retrieval "worked."
Embedding drift and mismatch. Embedding models have their own biases and blind spots. A question phrased one way might retrieve perfect results; rephrased slightly, it might miss entirely. This is invisible to end users and difficult to debug, even for technical teams.
The black box problem. When a RAG system gives a wrong answer, tracing the failure is hard. Was the chunking bad? The embedding? The retrieval threshold? The prompt? The model itself? With multiple moving parts, root cause analysis becomes a time-consuming detective exercise.
Maintenance overhead. RAG pipelines require ongoing care — re-embedding when documents change, monitoring retrieval quality, tuning chunk sizes, managing vector database infrastructure. For organizations without dedicated ML engineering teams, this becomes a significant burden.
The LLM Knowledge Base architecture addresses many of these issues through simplicity and transparency:
| Challenge | RAG Approach | LLM Knowledge Base Approach |
|---|---|---|
| Knowledge representation | Fragmented chunks in vector space | Coherent, structured markdown documents |
| Auditability | Opaque embeddings and retrieval scores | Human-readable files you can open and review |
| Failure debugging | Multi-step pipeline diagnosis | Read the document — is the information there or not? |
| Maintenance | Re-embed, re-index, monitor retrieval | Update the markdown files (humans or AI agents) |
| Non-technical access | Requires engineering tools | Anyone can read and edit markdown |
| Context quality | Retrieved fragments, possibly incomplete | Full, pre-organized context |
This doesn't mean the LLM Knowledge Base approach has zero failure modes — no architecture does. But its failure modes are visible. If the knowledge base document is wrong, you can see that it's wrong by reading it. If it's missing information, you can see the gap. That auditability is a meaningful advantage for businesses that need to trust their AI systems.
At Cloud Radix, we've seen firsthand how difficult it is for non-technical stakeholders to trust a system they can't inspect. Making the knowledge layer human-readable changes the conversation entirely.

How Do AI Agents Maintain the Knowledge Base?
This is where the architecture gets genuinely interesting — and where it connects directly to how we think about AI employees at Cloud Radix.
In Karpathy's model, the knowledge base isn't static. It's maintained by AI agents that continuously process new information, update existing documents, and reorganize the library as the organization evolves. Think of it less like a database and more like having a team of technical writers who work around the clock.
These maintenance agents handle several responsibilities:
Ingesting new information. When new documents arrive — policy updates, product changes, meeting notes, customer feedback — the agents read them, extract the relevant knowledge, and integrate it into the appropriate markdown files. They don't just append raw text; they synthesize and structure the information.
Updating existing documents. When a policy changes, the agent updates the relevant knowledge base document to reflect the new state. There's no stale chunk sitting in a vector database waiting to mislead someone — the document itself is the source of truth, and it's kept current.
Resolving conflicts. When new information contradicts existing knowledge base content, the agents flag the conflict and attempt to resolve it based on source authority and recency. This is a non-trivial capability, but it's precisely the kind of task that modern LLMs handle well.
Organizing and restructuring. As the knowledge base grows, agents can reorganize documents, split overly long files, merge redundant content, and maintain a consistent structure. The library stays navigable rather than accumulating cruft over time.
This agent-maintained approach has a critical advantage: the knowledge base reflects digested understanding, not raw document dumps. When you ask a RAG system about your company's return policy, it retrieves fragments of the original policy document. When you query the LLM Knowledge Base, the model reads a clearly structured summary that an agent has already written — complete with edge cases, exceptions, and cross-references.
This is directly aligned with how we deploy AI sub-agents for our clients. The concept of specialized agents maintaining domain-specific knowledge is already proving effective in production environments. Karpathy's architecture gives it a formal structure.
For organizations exploring AI automation, the maintenance agent pattern is particularly relevant. It's not just about answering questions — it's about maintaining the institutional knowledge that makes good answers possible.

When Should You Use This Architecture Instead of RAG?
Let's be clear about one thing: the LLM Knowledge Base architecture doesn't make RAG obsolete. Both approaches have their strengths, and the right choice depends on your specific use case.
The LLM Knowledge Base approach works best when:
- Your total knowledge corpus, once summarized and structured, fits within a large context window (roughly up to a few million tokens of source material that can be distilled into structured summaries).
- Auditability and trust are priorities — regulated industries, customer-facing applications, or organizations where non-technical leaders need to validate AI outputs.
- Your knowledge changes frequently and needs to stay current without re-embedding entire document sets.
- You want non-technical team members to be able to review, edit, and contribute to the knowledge base directly.
- You're building AI systems where context quality matters more than corpus breadth — better to have deeply understood information than fragments of everything.
RAG still makes more sense when:
- Your document corpus is genuinely massive — tens of millions of documents where even aggressive summarization can't reduce the knowledge to context-window size.
- You need real-time retrieval from rapidly changing data sources (live databases, streaming data).
- Your queries are highly specific and require pinpoint retrieval from large collections (e.g., finding a specific clause in thousands of legal contracts).
- You're working with multimedia content (images, audio, video) that doesn't condense well into text summaries.
Hybrid approaches are also viable. You might use the LLM Knowledge Base for your core organizational knowledge — policies, procedures, product information, FAQs — while maintaining a RAG pipeline for deep-dive retrieval into large document archives. The structured knowledge base handles 80% of queries with high accuracy; RAG fills in the long tail.
| Factor | LLM Knowledge Base | RAG | Hybrid |
|---|---|---|---|
| Corpus size | Small to medium | Any size | Any size |
| Auditability | High | Low | Medium |
| Setup complexity | Lower | Higher | Highest |
| Maintenance burden | Agent-managed docs | Pipeline monitoring | Both |
| Context quality | High (curated) | Variable (retrieved) | High for core, variable for edge |
| Best for | Core business knowledge | Large document archives | Most production systems |
For most mid-market businesses — the kind we work with across Northeast Indiana and beyond — the LLM Knowledge Base approach is likely the better starting point. Your organizational knowledge isn't Google-scale. It's the collected expertise of your team, your processes, your customer relationships. That knowledge can be curated, structured, and loaded into context far more effectively than it can be chunked and embedded.

What Does This Mean for AI Security and Governance?
One dimension of this architecture that deserves attention is governance. When your knowledge base is a collection of readable markdown files maintained by AI agents, you gain something that's extremely difficult to achieve with RAG: inspectable AI inputs.
In a RAG system, the context that shapes an AI's response is dynamically assembled at query time. You can log what was retrieved, but reviewing those logs requires technical expertise and tooling. In the LLM Knowledge Base model, the context is the knowledge base itself — and anyone can read it.
This has real implications for organizations that need to comply with AI governance frameworks, industry regulations, or internal audit requirements. If a secure AI gateway is the front door of your AI security strategy, then an inspectable knowledge base is the floor plan — it lets you see exactly what the system knows and verify that it's correct.
Karpathy's architecture also simplifies access control. You can organize knowledge base documents by sensitivity level and control which documents are loaded into context for which users or use cases. It's not perfectly granular, but it's straightforward in a way that row-level vector database permissions are not.
The version control story is also compelling. Markdown files live naturally in Git repositories, which means you get full change history, branching, pull request reviews, and rollback capability — all with tools that development teams already use. Try getting that kind of auditability from a vector database.
For organizations in regulated industries — healthcare, finance, manufacturing — this transparency isn't a nice-to-have. It's increasingly becoming a requirement as AI governance frameworks mature.

What Does This Mean for Fort Wayne and Northeast Indiana Businesses?
Here in Northeast Indiana, we're watching a practical shift in how regional businesses approach AI. The companies we work with at Cloud Radix — manufacturers, professional services firms, healthcare organizations, logistics operators — aren't building AI systems for research papers. They're building them to make their teams more effective.
Karpathy's architecture resonates particularly well in this market for a simple reason: it's buildable with the teams you already have.
A RAG pipeline requires someone who understands embedding models, vector databases, chunking strategies, and retrieval tuning. That's specialized ML engineering talent, and it's hard to find anywhere — let alone in a regional market. The LLM Knowledge Base approach, by contrast, requires someone who can write well-structured documents and manage AI agents. That's a fundamentally different skill set, and it's far more accessible.
For Fort Wayne businesses exploring AI, this architecture lowers the barrier to entry meaningfully. Your operations manager can review the knowledge base. Your compliance officer can audit it. Your subject matter experts can contribute to it directly. The AI system becomes something the whole organization can participate in, not just the engineering team.
We've been deploying AI employees with our clients across the region, and the single most common concern we hear is, "How do I know it's using the right information?" The LLM Knowledge Base architecture gives a concrete answer: open the files and read them.
That kind of transparency builds trust. And trust is what turns an AI pilot project into an AI strategy.
Ready to Move Beyond RAG?
Karpathy's LLM Knowledge Base architecture isn't just a theoretical alternative — it's a practical blueprint for building AI systems that are simpler, more transparent, and easier for your team to own.
At Cloud Radix, we help businesses in Fort Wayne, Northeast Indiana, and beyond design and deploy AI architectures that match their actual needs — not the most complex option, but the right one. Whether you're evaluating your current RAG pipeline, exploring AI employees for the first time, or looking for a knowledge management approach your whole team can trust, we're ready to help.
Talk to our AI consulting team about what Karpathy's architecture could look like for your organization. Or explore how our AI employees can maintain a living knowledge base tailored to your business.