
Your AI agent has your Salesforce credentials, your Slack token, and read access to your production database. Right now, those credentials are sitting inside the same execution environment where the agent processes untrusted input from users, emails, and third-party integrations.
If that doesn't make you uncomfortable, it should.
According to VentureBeat's analysis of two new zero-trust architectures, 43% of organizations still use shared service accounts for their AI agents, and 68% cannot distinguish agent activity from human activity in their logs. We're handing broad access to autonomous systems and then losing them in the noise.
The good news: April 2026 brought two serious responses to this problem. Anthropic launched Managed Agents in public beta on April 8, and Nvidia's NemoClaw hit early preview in March. Both tackle credential isolation for AI agents, but they take fundamentally different approaches to where the blast radius stops. Understanding the difference matters for every organization deploying AI employees into production workflows.
This isn't theoretical. If you've already started thinking about how AI fits your security posture, our AI Employee Security Checklist covers the fundamentals. What follows goes deeper into the architectural decisions that separate a contained incident from a breach.
Key Takeaways
- 43% of organizations use shared service accounts for AI agents, and 68% cannot tell agent from human activity in logs
- Anthropic's Managed Agents architecture structurally separates the AI brain from credentials, so a compromised sandbox yields nothing reusable
- Nvidia's NemoClaw takes a different approach: wrapping the agent in four kernel-level security layers rather than splitting it into separate components
- Credential isolation is the single most important architectural decision when deploying AI agents in 2026
- Data drift in security ML models creates blind spots that adversaries are already exploiting alongside AI agent deployments
- Organizations need agent-specific credentials, append-only audit logs, and default-deny networking as baseline requirements

Why Are AI Agent Credentials the Biggest Unaddressed Attack Surface in 2026?
The scale of the problem is staggering. According to PwC's 2026 enterprise survey, 79% of organizations now use AI agents in at least one business function. But a Gravitee survey found that only 14.4% of those deployments have full security team approval. The rest were stood up by business units, IT teams, or individual developers — often with shared service accounts and broad permissions because that was the fastest path to production.
The core architectural problem is deceptively simple. Traditional applications authenticate once and operate within defined boundaries. AI agents are different: they reason about tasks, decide which tools to invoke, and often need credentials for multiple systems to complete a single workflow. A customer service agent might need your CRM, email system, knowledge base, and billing platform — all within a single interaction.
Most organizations solve this by giving the agent a service account with access to everything it might need. That's convenient. It's also a single point of compromise that hands an attacker the keys to every system the agent touches.
The credential isolation problem compounds when you consider how AI agents handle input. Unlike traditional APIs that process structured data, AI agents process natural language from users, emails, documents, and third-party systems. Every piece of untrusted input is an opportunity for prompt injection — and if the agent's credentials are in the same execution environment where it processes that input, a successful injection doesn't just manipulate the agent's behavior. It potentially compromises every credential the agent holds.
The Cloud Security Alliance reports that only 26% of organizations have governance policies specifically addressing AI agent access. And 52% rely on workload identities — machine-to-machine credentials — that were designed for traditional microservices, not autonomous agents that make dynamic decisions about which systems to call and when.
We covered the broader landscape of AI failure modes in our guide to 42 Ways AI Can Break Your Business. Credential exposure is the single highest-impact risk on that list, because it turns every other vulnerability into a potential breach.
How Does Anthropic's Managed Agents Architecture Isolate Credentials?
Anthropic's approach, launched in public beta on April 8, 2026, is architecturally radical in its simplicity. Instead of trying to secure the agent's execution environment, they split the agent into three components that don't trust each other.
The Brain is the reasoning component — Claude's language model running in an isolated sandbox. It plans tasks, generates instructions, and processes results. Critically, the brain never sees raw credentials. It doesn't know your Salesforce password. It doesn't hold your API keys. It works with opaque references that have no value outside the managed infrastructure.
The Hands are execution components that carry out actions in external systems. OAuth tokens and API credentials live in an external vault that the brain cannot access directly. When the brain decides to create a Salesforce record, it issues a structured instruction to the hands, which authenticate through a session-bound proxy. The proxy injects the credential at the network layer, executes the action, and returns only the result to the brain.
The Session is an append-only event log that records every instruction, every action, and every result. This log lives outside both the brain and the hands — neither component can modify or delete it. If the brain is compromised, the session log captures everything the compromised agent attempted. If the hands are compromised, the log shows which credentials were used and what actions were taken.
The security insight is structural: because credentials never enter the brain's sandbox, a prompt injection that compromises the reasoning layer yields nothing reusable. The attacker might manipulate what the agent does, but they can't extract credentials to use outside the managed environment. Single-hop exfiltration — the most common attack pattern against AI agents — is eliminated by architecture, not by detection.
The trade-off is performance. Anthropic reports approximately 60% reduced time-to-first-byte (TTFB) compared to direct API calls, because every action routes through the session-bound proxy. For real-time applications, that latency matters. For business workflows where security outweighs milliseconds, it's an acceptable cost.
Pricing sits at $0.08 per session-hour of active runtime, with idle time excluded, plus standard API token costs. That covers the managed infrastructure — the external vault, the session proxy, the disposable containers, and the append-only logging.
We analyzed the broader business implications of Anthropic's platform strategy in our piece on Anthropic's AI Agent Lockout. Managed Agents represents the security layer that makes their agent ecosystem viable for enterprise deployment.
How Does Nvidia's NemoClaw Compare to Anthropic's Approach?
Where Anthropic separates the agent into non-trusting components, Nvidia's NemoClaw — which hit early preview on March 16, 2026 — takes the opposite philosophy: keep the agent whole, but wrap it in stacked security layers that contain any compromise.
NemoClaw implements four distinct security layers, each addressing a different attack vector:
Layer 1: Sandboxed Execution. Every agent runs inside a Landlock/seccomp/namespace sandbox that restricts filesystem access, system calls, and process creation at the kernel level. Even if the agent's code is compromised, it cannot escape the sandbox to access the host system. This is containment in the traditional security sense — limiting what a compromised process can reach.
Layer 2: Default-Deny Networking. All network connections are blocked by default. Allowed connections are specified in a YAML policy file that defines exactly which endpoints the agent can reach, on which ports, using which protocols. This prevents data exfiltration to unauthorized endpoints — a compromised agent that can't phone home is significantly less dangerous. The approach mirrors what we outlined in our analysis of Shadow AI Is Your Biggest Data Risk in 2026.
Layer 3: Privacy Router. NemoClaw integrates Nvidia's Nemotron models to route sensitive queries to local inference rather than sending them to external API endpoints. If the agent needs to process PII, financial data, or confidential documents, the privacy router keeps that data on-premises. This is a meaningful differentiator for regulated industries — healthcare, legal, and financial services organizations that cannot send certain data categories to third-party APIs regardless of the provider's security posture.
Layer 4: Intent Verification. Before any high-impact action — sending an email, modifying a database, transferring funds — NemoClaw's OpenShell component intercepts the action and verifies it against the original user intent. This is behavioral defense: even if a prompt injection manipulates the agent into attempting an unauthorized action, the intent verification layer catches the mismatch between what the user asked for and what the agent is trying to do. It's conceptually similar to the human approval gate pattern, but automated.
Anthropic Managed Agents vs. Nvidia NemoClaw: Architectural Comparison
| Feature | Anthropic Managed Agents | Nvidia NemoClaw |
|---|---|---|
| Architecture philosophy | Separation — split agent into non-trusting components | Containment — wrap agent in stacked security layers |
| Credential storage | External vault, never enters sandbox | API keys proxied; messaging tokens as env vars in sandbox |
| Blast radius on compromise | Nothing reusable in sandbox | Contained by kernel-level restrictions |
| Prompt injection defense | Structural — credentials unreachable | Behavioral — intent verification intercepts actions |
| Networking model | Session-bound proxy for all external calls | Default-deny with YAML policy allowlists |
| Audit logging | Append-only event log, external to agent and container | Real-time TUI logging of all actions and connections |
| State persistence | External event log survives container crashes | No external recovery mechanism (data-loss risk) |
| Privacy routing | Not specified | Sensitive queries routed to local Nemotron models |
| Maturity | Public beta (April 8, 2026) | Early preview (March 16, 2026) |
| Pricing | $0.08/session-hour + API token costs | Not publicly disclosed |
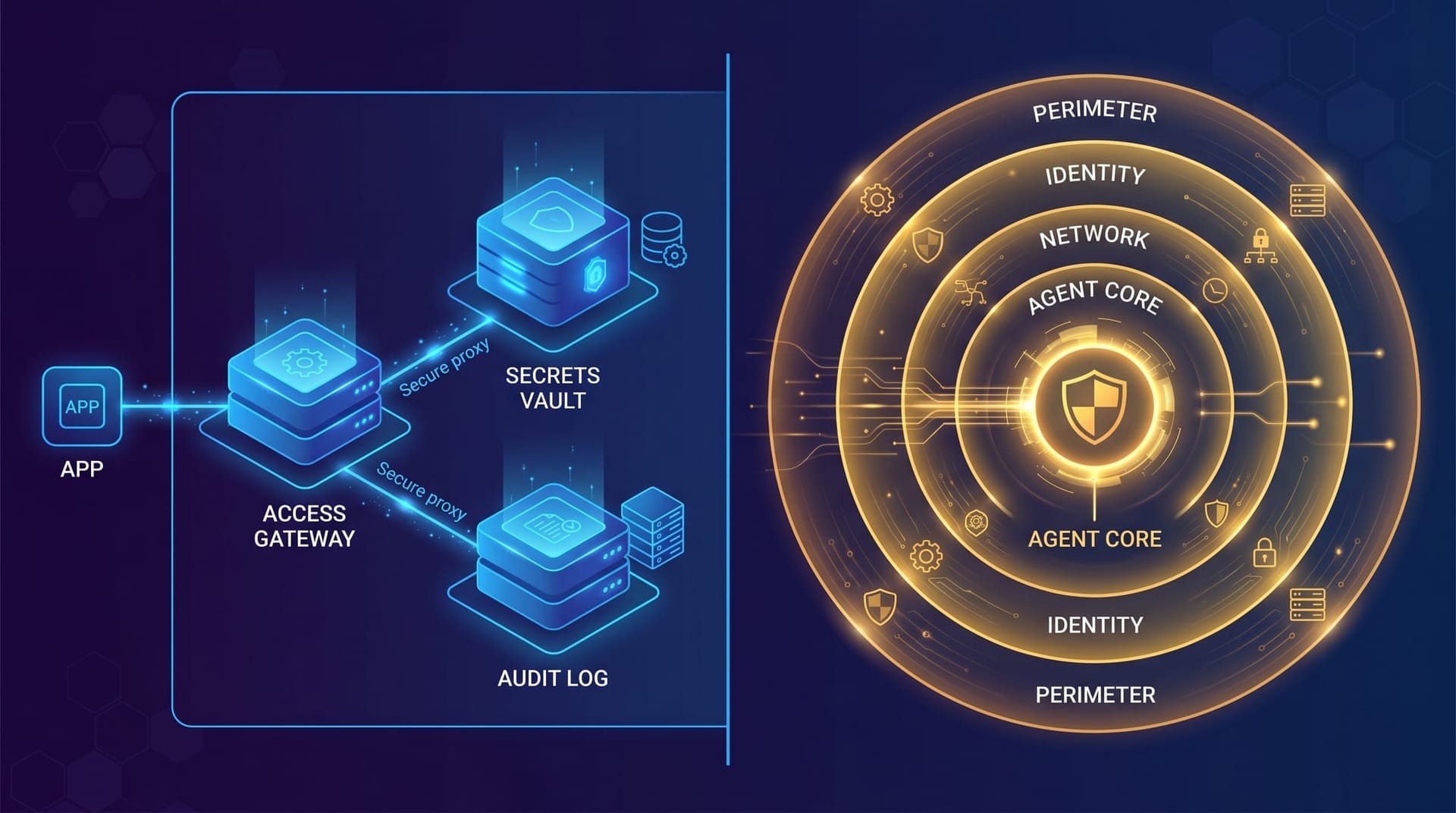
The bottom line: Anthropic offers stronger credential isolation through structural separation — credentials literally cannot be reached from the agent's execution environment. NemoClaw offers stronger execution containment and a privacy routing layer that matters for regulated industries. Neither is universally superior. The right choice depends on whether your primary threat model is credential exfiltration (favor Anthropic) or execution containment with data residency requirements (favor NemoClaw).
What Does Data Drift Mean for AI Agent Security Models?
Credential isolation is a structural control. But most organizations also rely on ML-based behavioral monitoring to detect anomalous agent activity — unusual API calls, unexpected data access patterns, suspicious network connections. Those models have a problem that's getting worse: data drift.
VentureBeat reported on April 12, 2026 that security teams are seeing five warning signs that their ML-based detection models have drifted beyond useful accuracy:
- Declining accuracy in key detection metrics — false positive rates climbing, true positive rates dropping, without any change to the underlying model.
- Feature distribution changes — the statistical properties of input features have shifted from the training baseline. API call patterns, network traffic volumes, and user behavior profiles all evolve as AI agents become more prevalent in production.
- Prediction output drift — the model's outputs trend in one direction without corresponding changes in ground truth. A security model that gradually classifies more activity as “normal” is drifting toward blindness.
- Decreasing confidence scores — the model becomes less certain across all predictions, indicating that incoming data no longer matches what it was trained to evaluate.
- Feature relationship shifts — the correlations between features that the model depends on have changed. If API call frequency used to correlate with time of day but AI agents now make calls 24/7, models trained on human activity patterns will misclassify agent behavior.
The practical tools for detecting drift are well-established: the Kolmogorov-Smirnov (KS) test compares the distribution of current input features against the training baseline, and the Population Stability Index (PSI) quantifies how much the overall prediction landscape has shifted. But most security teams aren't running these checks regularly on their detection models.
The intersection with AI agent security is particularly dangerous. As organizations deploy more agents, the behavior patterns in their networks change fundamentally. Models trained on human activity patterns become progressively less accurate at detecting anomalies in agent activity. Adversaries who understand this can time their attacks to coincide with periods of maximum drift — exploiting the gap between what the security model expects and what's actually happening.
Consider an echo-spoofing attack: an adversary crafts agent interactions that gradually shift the behavioral baseline, making genuinely malicious actions look like normal agent behavior. If the security model isn't recalibrated to account for legitimate agent activity, the attacker's actions blend into the new normal.
This is why structural controls like credential isolation matter more than behavioral monitoring alone. A drifted detection model might miss the attack. But if credentials aren't in the execution environment, there's nothing for the attacker to take. Our AI Employee Governance Playbook outlines the full governance framework, including when to retrain security models and how to layer structural controls alongside behavioral detection.
Why Is Local AI Inference a Hidden Credential Risk?
While organizations focus on securing cloud-hosted AI agents, a parallel risk is growing on employee workstations. VentureBeat reported that developers and power users are increasingly running AI models locally — using tools like Ollama, llama.cpp, and LM Studio to run large language models on their own hardware without any network-based security monitoring.
This is the shadow AI problem in its most dangerous form. When an AI model runs locally, it has access to every file, credential, and API token stored on that machine. Local models operate outside your network security perimeter, bypass your DLP controls, and leave no audit trail in your centralized logging systems.
The threat breaks down into three dimensions:
Dimension 1: Unmonitored credential access. A locally running AI agent can read SSH keys, API tokens stored in environment variables, browser cookies, and credential files from tools like AWS CLI or kubectl. If the model is compromised — through a malicious fine-tune, a poisoned model weight, or a supply chain attack on the model distribution pipeline — those credentials are immediately available for exfiltration.
Dimension 2: No behavioral baseline. Your security team has no visibility into what a locally running model is doing. They can't detect anomalous API calls because the calls originate from the user's workstation with the user's credentials. From the network's perspective, a compromised local AI agent looks identical to the legitimate user.
Dimension 3: Supply chain opacity. Models downloaded from Hugging Face, Ollama registries, or shared via file transfer have no standardized integrity verification. Unlike software packages with signed checksums and vulnerability databases, AI models are opaque blobs of weights. A malicious actor could distribute a model that functions normally on most inputs but exfiltrates credentials when it encounters specific patterns — and there's currently no standard tooling to detect this.
The detection signals exist if you know where to look: .gguf and .safetensors files appearing on workstations, Ollama running on port 11434, unexplained GPU utilization spikes, and network connections to model registries. But most endpoint detection and response (EDR) tools aren't configured to flag these indicators.
The emerging concept of a model SBOM (Software Bill of Materials) — a standardized manifest of a model's training data, architecture, and provenance — could eventually address the supply chain problem. But in 2026, it remains a proposal, not a production capability.
This is exactly the gap between consumer AI tools and enterprise AI employees. Consumer tools give individuals power with no guardrails. Enterprise AI employees operate within an architecture designed for visibility, control, and credential isolation.
What Should a Zero-Trust AI Agent Deployment Look Like Today?
Based on the architectures from Anthropic and Nvidia, the data drift research, and the local inference risks, here are seven requirements for any organization deploying AI agents into production in 2026:
- Agent-specific credentials with minimum-privilege scope. Every AI agent gets its own identity — not a shared service account, not a developer's personal credentials. Each credential set is scoped to exactly the permissions that agent needs for its specific function. A customer service agent doesn't need write access to your financial systems.
- Credential isolation from the execution environment. Credentials should never exist in the same process space where the agent reasons about untrusted input. Anthropic's external vault pattern is the gold standard: the agent works with opaque references, and credentials are injected at the network layer by infrastructure the agent cannot access.
- Default-deny networking with explicit allowlists. AI agents should not have unrestricted network access. Define exactly which endpoints, ports, and protocols each agent can use. NemoClaw's YAML policy approach provides a practical implementation pattern.
- Append-only audit logging external to the agent. Every action the agent takes, every credential it uses, and every external connection it makes should be logged in a system the agent cannot modify or delete. This is essential for both security forensics and compliance.
- Human approval gates for high-impact actions. Any action that modifies financial records, sends external communications, or changes system configurations should require human approval before execution. Automated intent verification is a useful supplement, but human judgment remains the strongest defense for irreversible actions.
- Continuous drift monitoring for security ML models. Run KS tests and PSI calculations on your behavioral detection models at least weekly. When drift exceeds your threshold, retrain immediately — don't wait for a scheduled update cycle.
- Local inference policy and enforcement. Establish clear policies on which AI models can run on employee workstations, with technical enforcement via EDR rules that flag unauthorized model files and inference processes. Consider routing all AI inference through your Secure AI Gateway to maintain visibility and control.
None of these requirements are exotic. They're standard zero-trust principles applied to a new class of autonomous system. The challenge isn't technical complexity — it's organizational willingness to treat AI agents with the same security rigor as human employees.
How Should Fort Wayne Businesses Approach Zero-Trust AI Agent Security?
The national conversation around AI agent security can feel distant from a 30-person manufacturing company in Fort Wayne or a regional services firm in Northeast Indiana. But the credential risks are identical regardless of company size — and in many ways, the consequences are more severe for mid-market businesses.
A Fortune 500 company that suffers a credential compromise has redundant systems, dedicated incident response teams, and cyber insurance policies calibrated for the risk. A mid-market company that loses control of its CRM credentials, financial system access, or customer data faces an existential threat with fewer resources to respond.
The advantage Fort Wayne businesses have right now is timing. Most are in the early stages of AI agent deployment. That means credential isolation, audit logging, and zero-trust networking can be built into the architecture from day one — not retrofitted after an incident forces the conversation.
The proportional approach matters here. You don't need to replicate Anthropic's managed infrastructure or build Nvidia-grade kernel sandboxes. You need:
- AI agents running through a Secure AI Gateway that provides credential isolation, audit logging, and network control
- Agent-specific credentials scoped to minimum necessary permissions
- Human approval gates on any action that touches financial data, external communications, or system configurations
- A clear policy on which AI tools employees can use and where AI models can run
- Regular security reviews as your AI deployment expands
That's the foundation. It's achievable for any business size, and it's dramatically more secure than the 43% of organizations currently running agents on shared service accounts with no visibility.
If you're deploying AI agents or considering it, reach out. We'll walk through your specific architecture and identify where credential isolation matters most for your workflows.

Take Control of Your AI Agent Credentials Now
The credential isolation problem isn't going to solve itself, and it's getting more urgent as AI agent deployments accelerate. The architectures from Anthropic and Nvidia show that the industry recognizes the risk. What matters now is whether your organization acts before an incident forces the conversation.
Start with our AI Employee Security Checklist to assess your current posture. Then explore our Secure AI Gateway to see how credential isolation, audit logging, and zero-trust networking work in practice for mid-market businesses.
Frequently Asked Questions
Q1.What is zero-trust architecture for AI agents?
Zero-trust architecture for AI agents applies the principle of “never trust, always verify” to autonomous AI systems. Instead of granting agents broad access to credentials and systems, every action is authenticated, every connection is policy-controlled, and the agent’s execution environment is isolated from sensitive credentials. Both Anthropic’s Managed Agents and Nvidia’s NemoClaw implement versions of this approach, though with different architectural trade-offs.
Q2.Why is credential isolation more important than behavioral monitoring for AI agents?
Behavioral monitoring relies on ML models that can degrade through data drift — when the statistical properties of input data change over time, detection accuracy declines. Credential isolation is a structural control: if credentials aren’t in the execution environment, they can’t be exfiltrated regardless of whether your monitoring catches the attempt. Organizations should implement both, but credential isolation provides a harder security guarantee.
Q3.What is the difference between Anthropic Managed Agents and Nvidia NemoClaw?
Anthropic’s approach separates the agent into three non-trusting components (brain, hands, session log) and stores credentials in an external vault that the agent never accesses directly. NemoClaw wraps the entire agent in four kernel-level security layers (sandboxed execution, default-deny networking, privacy routing, intent verification) and monitors all behavior. Anthropic offers stronger credential isolation; NemoClaw offers stronger execution containment and local inference for privacy-sensitive workloads.
Q4.How much does Anthropic Managed Agents cost?
Anthropic’s Managed Agents pricing is $0.08 per session-hour of active runtime, with idle time excluded, plus standard API token costs. This covers the managed infrastructure including the external credential vault, session-bound proxy, disposable containers, and append-only event logging. Nvidia has not publicly disclosed NemoClaw pricing as of April 2026.
Q5.Can AI agents be compromised through indirect prompt injection?
Yes. Indirect prompt injection occurs when untrusted data processed by the agent contains instructions that manipulate its behavior. If the agent has direct access to credentials in its execution environment, a successful prompt injection could potentially leverage those credentials for unauthorized actions. This is precisely why Anthropic’s Managed Agents architecture keeps credentials in an external vault — even a successful injection cannot reach them because they are structurally separated from the agent’s sandbox.
Q6.What are the signs that security ML models monitoring AI agents have drifted?
Five key indicators: declining accuracy in key detection metrics, changes in feature distributions compared to training data, prediction outputs trending in one direction without corresponding ground-truth changes, decreasing confidence scores across the model’s outputs, and shifts in the relationships between features the model depends on. Statistical tools like the Kolmogorov-Smirnov test and Population Stability Index can quantify drift before it leads to missed detections.
Q7.Should small and mid-market businesses worry about AI agent credential security?
Absolutely. The 43% of organizations using shared service accounts for AI agents includes businesses of all sizes. For mid-market companies, the impact of a credential compromise is often proportionally larger because there are fewer redundant systems and smaller security teams to respond. The advantage is that smaller organizations deploying agents now can build credential isolation into their architecture from the start, rather than retrofitting it after an incident.
Sources & Further Reading
- VentureBeat: venturebeat.com — AI agent zero-trust architecture: credential isolation from Anthropic and Nvidia — Deep analysis of two competing approaches to securing AI agent credentials in production.
- VentureBeat: venturebeat.com — Five signs data drift is already undermining your security models — How statistical drift in ML-based security models creates blind spots adversaries exploit.
- VentureBeat: venturebeat.com — On-device inference is the CISO's new blind spot — The credential and compliance risks of local AI model execution on employee workstations.
Secure Your AI Agent Credentials Now
We help Fort Wayne and Northeast Indiana businesses deploy AI agents with credential isolation, audit logging, and zero-trust architecture built in from day one.
Schedule a Free ConsultationNo contracts. No pressure. Just an honest conversation about securing your AI infrastructure.


